9. Python DataPlugins¶
Create a DataPlugin to load, register, or search your custom file formats in LabVIEW or DIAdem, or to index, browse, and find your file formats with SystemLink DataFinder.
You can also create DataPlugins using C++, VBS, LabVIEW, or Python.
Note
Browse through 230+ DataPlugins in the NI Store to check whether there is an existing DataPlugin for your data format.
9.1 Getting Started¶
Python DataPlugins consist of only one Python file that contains all the logic. Almost all language features of the official Python 3.5.9 and its base libraries can be used.
You can create Python DataPlugins in your favorite editor. Recommended:
- NI DIAdem >= 2020
- VSCode with the NI Python DataPlugin Extension
9.1.1 Plugin Class¶
Start writing your DataPlugin by implementing
class Plugin:
The class name cannot be changed.
9.1.2 Read Store¶
You need to implement a read_store method in every Python DataPlugin. This method is called by DIAdem, LabVIEW, or SystemLink DataFinder when attempting to open your data file. The applications pass a set of useful parameters that can be accessed by the parameter array.
Example Code
import datetime
import os
from pathlib import Path
def read_store(self, parameter):
"""
Reads data file and returns a Python dictionary
that contains groups and channels in a TDM-like structure.
"""
# String: Contains the absolute path to the data file
file_path = os.path.realpath(parameter["file"])
# Boolean: Denotes whether data file was accessed by SystemLink DataFinder
# => the bulk data was not touched.
is_datafinder_indexer = parameter["datafinder"]
tdm_tree = {
"author": "NI",
"description": "File containing a json dict read by Python plugin",
"groups": [{
"name": "Group_1",
"description": "First group",
"channels": [{
"name": "Index",
"description": "",
"info": "Going up",
"unit_string": "s",
"type": "DataTypeChnFloat64",
"values": [1, 2, 3]
}, {
"name": "Vals_1",
"description": "",
"unit_string": "km/h",
"type": "DataTypeChnFloat64",
"values": [1.1, 2.1, 3.1]
}, {
"name": "Vals_2",
"description": "",
"unit_string": "km/h",
"type": "DataTypeChnFloat64",
"values": [1.2, 2.2, 3.2]
}, {
"name": "Str_1",
"description": "",
"type": "DataTypeChnString",
"values": ["abc", "def", "hij"]
}]
}, {
"name": "Group_2",
"description": "Second group",
"channels": [{
"name": "Index",
"description": "",
"info": "Going up",
"unit_string": "s",
"type": "DataTypeChnFloat64",
"values": [1, 2, 3, 4]
}
]
}]
}
return {Path(file_path).stem: tdm_tree}
Use the file parameter to access your file using text, CSV, or binary readers. The data must be added to a Python dictionary. It represents the structure of tdm/tdms files that consists of one root, 0...m groups, and 0...n channels:
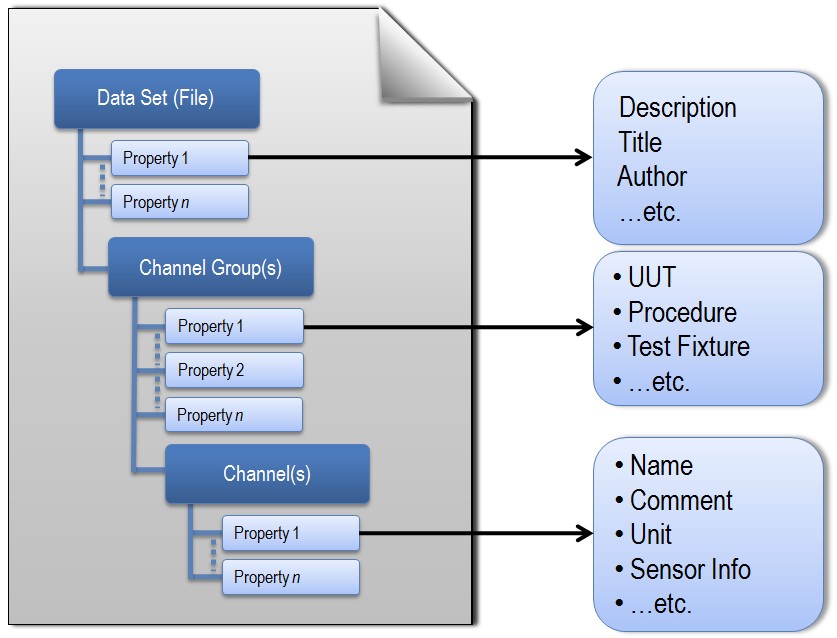
Example dictionary
self.tdm_tree = {
"author": "NI",
"description": "Example file",
"groups": [{
"name": "Example",
"description": "First group",
"time": datetime.datetime(2020, 2, 11, 15, 31, 59, 342380),
"channels": [{
"name": "Channel_0",
"description": "",
"values": [1.2, 1.3, 1.4],
"info": "Time in seconds",
"type": "DataTypeChnFloat64"
}, {
"name": "Channel_1",
"description": "",
"values": [10, 11, 12],
"unit_string": "km/h",
"type": "DataTypeChnFloat64"
}]
}]
}
file_path = os.path.realpath(parameter["file"])
return {Path(file_path).stem: self.tdm_tree}
Dictionary Schema
import datetime
from schema import And, Schema
Schema({
Optional('author'): str,
Optional('description'): str,
'groups': [{
'name': str,
Optional('description'): str,
Optional('time'): datetime.datetime,
'channels': [{
'name': str,
Optional('description'): str,
'values': list,
Optional('unit_string'): str,
'type': And(str, lambda s: s in (
'DataTypeChnFloat32',
'DataTypeChnFloat64',
'DataTypeChnString',
'DataTypeChnDate',
'DataTypeChnUInt8',
'DataTypeChnInt16',
'DataTypeChnInt32',
'DataTypeChnInt64'))
}]
}]}, ignore_extra_keys=True)
See full example: csv-read-with-direct-loading
9.2 Callback Loading¶
When handling a big data set, you might not want to load all data at the same time. To ensure the DataPlugin only returns values that applications request:
-
Assign an empty array to the channel values property:
... 'groups': [{ ... 'channels': [{ ... 'values': [], }] }] -
Outsource the functionality to load the bulk data values in a separate function. The function has the following definition:
def read_channel_values(self, grp_index, chn_index, numberToSkip, numberToTake): """ Returns a value array of the correct data type specified in the TDM dictionary """
Example Code
def read_channel_values(self, grp_index, chn_index, numberToSkip, numberToTake):
dataType = self.tdm_tree["groups"][grp_index]["channels"][chn_index]["type"]
values = []
for row in self.data:
value = row[self.channelNames[chn_index]]
values.append(value)
return values[numberToSkip:numberToTake+numberToSkip]
The client applications call this function to retrieve channel values (or
a subset of values). You need to implement the function to return the
values for a given group and channel index. You also need to ensure only the
correct subset of values is returned for a given numberToSkip and numberToTake.
In addition, you need to implement a callback function to retrieve the channel length. If all channels have the same length, it simply returns a constant.
def read_channel_length(self, grp_index, chn_index):
"""
Returns the channel length as an Integer for a given group and channel index
"""
return 10
See full example: csv-read-with-callback-loading
9.3 Error Handling¶
Python DataPlugins can raise errors in all callback functions. The raised error is displayed in DIAdem, LabVIEW, or SystemLink DataFinder.
def read_store(self, parameter):
...
raise Exception("Leave read_store with exception")
9.3.1 Not My File¶
A special case is "Not My File". This error should be raised when the DataPlugin
detects that the file to be opened is not suited for this DataPlugin. This
special error can be raised only in the read_store function by returning None:
def read_store(self, parameter):
...
if notMyFile:
return None
9.4 Export DataPlugin¶
Export Python DataPlugins to make them available on other systems. Use NI DIAdem to export a DataPlugin as a URI file.
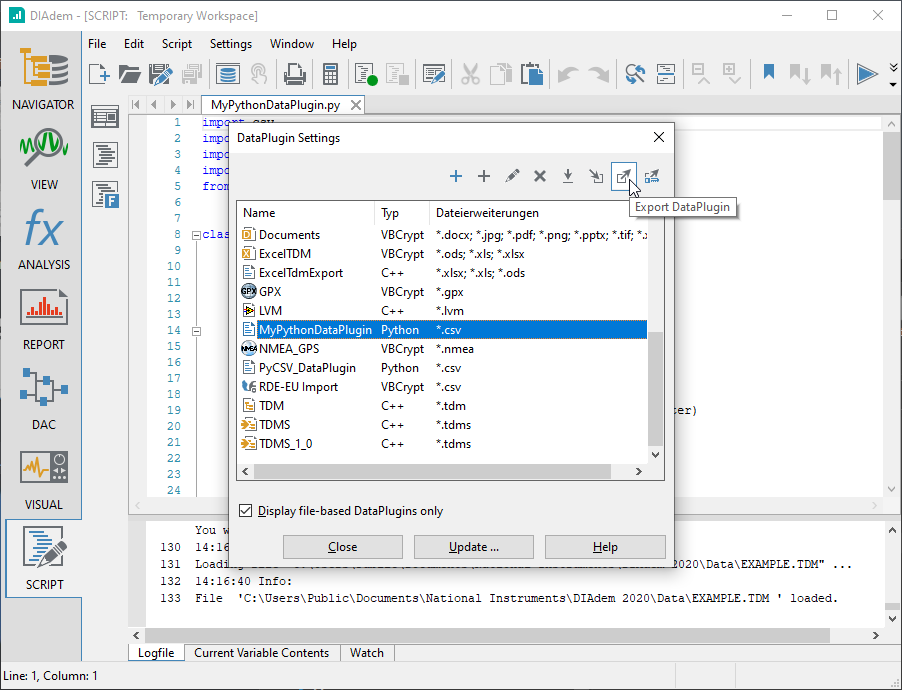
You can also export a DataPlugin from NI's Python DataPlugin Extension for Visual Studio Code:
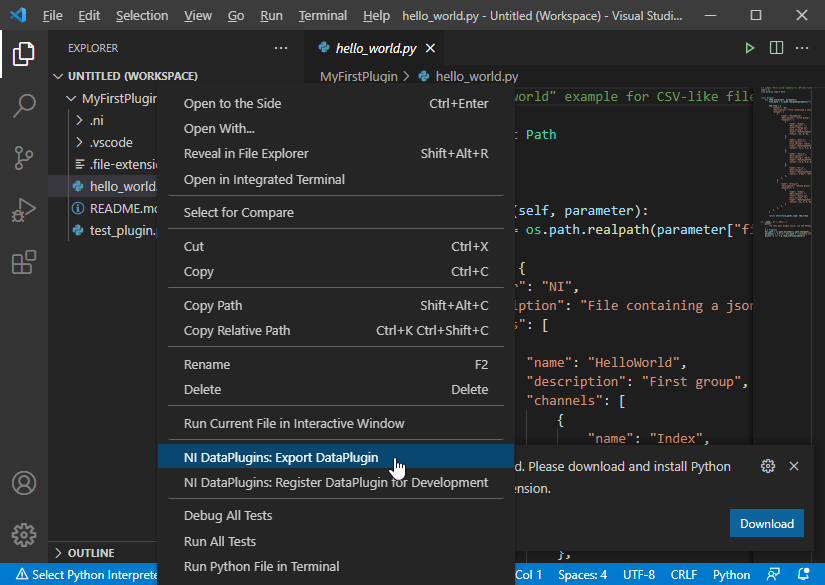
9.4.1 Encrypted DataPlugins¶
In some cases, you may want to protect your code from being viewed by others. Use NI DIAdem to export an encrypted Python DataPlugin. This functionality is not available in the VSCode extension.
9.5 Known Limitations¶
9.5.1 NumPy and Pandas¶
NumPy and Pandas do not run reliably in embedded Python environments and, therefore, NI does not recommend them for use in DataPlugins.
9.5.2 Single File DataPlugins¶
Python DataPlugins can only be written in a single Python file. Importing sidecar files is not supported. It will fail when exporting the DataPlugin as a URI.
9.5.3 datetime.strptime¶
There is an open issue in Python for
datetime.strptime that prevents the function from working properly in embedded
Python environments. Avoid using this function in DataPlugin source code.
Instead, add the following function to your code:
def strptime(self, value, format):
return datetime.datetime(*(time.strptime(value, "%d.%m.%y %H:%M:%S")[0:6]))